Interactive online version:
Image Classification with VGG and ResNet
This tutorial will introduce the attribution of image classifiers using VGG11 and ResNet18 trained on ImageNet. Feel free to replace VGG11 and ResNet18 with any other version of VGG or ResNet respectively.
Table of Contents
1. Preparation
First, we install Zennit. This includes its dependencies Pillow, torch and torchvision:
[1]:
%pip install zennit
/home/docs/checkouts/readthedocs.org/user_builds/zennit/envs/latest/bin/python: No module named pip
Note: you may need to restart the kernel to use updated packages.
Then, we import necessary modules, classes and functions:
[2]:
from itertools import islice
import torch
from torch.nn import Linear
from PIL import Image
from torchvision.transforms import Compose, Resize, CenterCrop
from torchvision.transforms import ToTensor, Normalize
from torchvision.models import vgg11_bn, vgg11, resnet18
from torchvision.models import VGG11_BN_Weights, VGG11_Weights, ResNet18_Weights
from zennit.attribution import Gradient, SmoothGrad
from zennit.core import Stabilizer
from zennit.composites import EpsilonGammaBox, EpsilonPlusFlat
from zennit.composites import SpecialFirstLayerMapComposite, NameMapComposite
from zennit.image import imgify, imsave
from zennit.rules import Epsilon, ZPlus, ZBox, Norm, Pass, Flat
from zennit.types import Convolution, Activation, AvgPool, Linear as AnyLinear
from zennit.types import BatchNorm
from zennit.torchvision import VGGCanonizer, ResNetCanonizer
We download an image of the Dornbusch Lighthouse from Wikimedia Commons:
{kind=link}
[3]:
torch.hub.download_url_to_file(
'https://upload.wikimedia.org/wikipedia/commons/thumb/8/8b/2006_09_06_180_Leuchtturm.jpg/640px-2006_09_06_181_Leuchtturm.jpg',
'dornbusch-lighthouse.jpg',
)
100.0%
We load and prepare the data. The image is resized such that the shorter side is 256 pixels in size, then center-cropped to (224, 224), converted to a torch.Tensor, and then normalized according the channel-wise mean and standard deviation of the ImageNet dataset:
[4]:
# define the base image transform
transform_img = Compose([
Resize(256),
CenterCrop(224),
])
# define the normalization transform
transform_norm = Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
# define the full tensor transform
transform = Compose([
transform_img,
ToTensor(),
transform_norm,
])
# load the image
image = Image.open('dornbusch-lighthouse.jpg')
# transform the PIL image and insert a batch-dimension
data = transform(image)[None]
We can look at the original image and the cropped image:
[5]:
# display the original image
display(image)
# display the resized and cropped image
display(transform_img(image))


Set this flag to True if you would like to use trained weights.
[6]:
use_trained_weights = False
2. VGG11 without BatchNorm
We start with VGG11 without BatchNorm. First, we initialize the VGG16 model and optionally load the hyperparameters.
[7]:
# load the model and set it to evaluation mode
weights = VGG11_Weights.DEFAULT if use_trained_weights else None
model = vgg11(weights=weights).eval()
2.1 Saliency Map
We first compute the Saliency Map, which is the absolute gradient, by using the Gradient Attributor:
[8]:
# choose a target class for the attribution (label 437 is lighthouse)
target = torch.eye(1000)[[437]]
# create the attributor, specifying model
with Gradient(model=model) as attributor:
# compute the model output and attribution
output, attribution = attributor(data, target)
print(f'Prediction: {output.argmax(1)[0].item()}')
Prediction: 635
Visualize the attribution:
[9]:
# absolute sum over the channels
relevance = attribution.abs().sum(1)
# create an image of the visualize attribution the relevance is only
# positive, so we use symmetric=False and an unsigned color-map
img = imgify(relevance, symmetric=False, cmap='hot')
# show the image
display(img)

2.2 SmoothGrad using Attributors
Model-agnostic attribution methods like SmoothGrad are implemented as Attributors. For these, we simply replace the Gradient Attributor, e.g., with the SmoothGrad Attributor:
[10]:
# choose a target class for the attribution (label 437 is lighthouse)
target = torch.eye(1000)[[437]]
# create the attributor, specifying model
with SmoothGrad(noise_level=0.1, n_iter=20, model=model) as attributor:
# compute the model output and attribution
output, attribution = attributor(data, target)
print(f'Prediction: {output.argmax(1)[0].item()}')
Prediction: 635
Visualize the attribution:
[11]:
# take the absolute and sum over the channels
relevance = attribution.abs().sum(1)
# create an image of the visualize attribution the relevance is only
# positive, so we use symmetric=False and an unsigned color-map
img = imgify(relevance, symmetric=False, cmap='hot')
# show the image
display(img)

2.3 Layer-wise Relevance Propagation (LRP) with EpsilonPlusFlat
We compute the LRP-attribution using the Gradient Attributor together with the EpsilonPlusFlat Composite:
[12]:
# create a composite
composite = EpsilonPlusFlat()
# choose a target class for the attribution (label 437 is lighthouse)
target = torch.eye(1000)[[437]]
# create the attributor, specifying model and composite
with Gradient(model=model, composite=composite) as attributor:
# compute the model output and attribution
output, attribution = attributor(data, target)
print(f'Prediction: {output.argmax(1)[0].item()}')
Prediction: 635
Visualize the attribution:
[13]:
# sum over the channels
relevance = attribution.sum(1)
# create an image of the visualize attribution
img = imgify(relevance, symmetric=True, cmap='coldnhot')
# show the image
display(img)
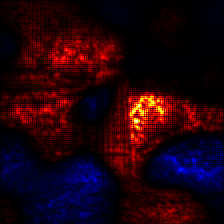
2.4 LRP with EpsilonGammaBox
We now compute the LRP-attribution with the EpsilonGammaBox Composite. The EpsilonGammaBox Composite uses the ZBox rule, which needs as arguments the lowest and highest possible values.
[14]:
# the EpsilonGammaBox composite needs the lowest and highest values, which are
# here for ImageNet 0. and 1. with a different normalization for each channel
low, high = transform_norm(torch.tensor([[[[[0.]]] * 3], [[[[1.]]] * 3]]))
# create a composite, specifying required arguments
composite = EpsilonGammaBox(low=low, high=high)
# choose a target class for the attribution (label 437 is lighthouse)
target = torch.eye(1000)[[437]]
# create the attributor, specifying model and composite
with Gradient(model=model, composite=composite) as attributor:
# compute the model output and attribution
output, attribution = attributor(data, target)
print(f'Prediction: {output.argmax(1)[0].item()}')
Prediction: 635
Visualize the attribution:
[15]:
# sum over the channels
relevance = attribution.sum(1)
# create an image of the visualize attribution
img = imgify(relevance, symmetric=True, cmap='coldnhot')
# show the image
display(img)
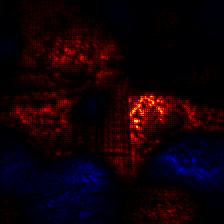
2.5 LRP with EpsilonGammaBox with modified epsilon and stabilizer
We again compute the LRP-attribution with the EpsilonGammaBox Composite. This time, we change the epsilon and stabilizer values, which both stabilize the denominator in their respective rules:
[16]:
# the EpsilonGammaBox composite needs the lowest and highest values, which are
# here for ImageNet 0. and 1. with a different normalization for each channel
low, high = transform_norm(torch.tensor([[[[[0.]]] * 3], [[[[1.]]] * 3]]))
# create a composite, specifying required arguments
composite = EpsilonGammaBox(
low=low,
high=high,
epsilon=Stabilizer(epsilon=0.1, norm_scale=True),
stabilizer=lambda x: ((x == 0.) + x.sign()) * x.abs().clip(min=1e-6),
)
# choose a target class for the attribution (label 437 is lighthouse)
target = torch.eye(1000)[[437]]
# create the attributor, specifying model and composite
with Gradient(model=model, composite=composite) as attributor:
# compute the model output and attribution
output, attribution = attributor(data, target)
print(f'Prediction: {output.argmax(1)[0].item()}')
Prediction: 635
Visualize the attribution:
[17]:
# sum over the channels
relevance = attribution.sum(1)
# create an image of the visualize attribution
img = imgify(relevance, symmetric=True, cmap='coldnhot')
# show the image
display(img)

2.6 More Visualization
We can try out different color-maps by either using another built-in color map, or using the color-map specification language:
[18]:
print('Built-in color-map bwr')
display(imgify(relevance, symmetric=True, cmap='bwr'))
print('CMLS code for color-map from cyan to grey to purple')
display(imgify(relevance, symmetric=True, cmap='0ff,444,f0f'))
print('CMSL code for grey scale for negative and red for positive values')
display(imgify(relevance, symmetric=True, cmap='fff,000,f00'))
Built-in color-map bwr

CMLS code for color-map from cyan to grey to purple

CMSL code for grey scale for negative and red for positive values

To directly save the visualized attribution, we can use imsave instead:
[19]:
# directly save the visualized attribution
imsave('attrib-1.png', relevance, symmetric=True, cmap='bwr')
3. VGG11 with BatchNorm
VGG11 with BatchNorm requires a canonizer for LRP to function properly. We initialize the VGG11-bn model and optionally load the hyperparameters.
[20]:
# load the model and set it to evaluation mode
weights = VGG11_BN_Weights.DEFAULT if use_trained_weights else None
model = vgg11_bn(weights=weights).eval()
3.1 LRP with EpsilonGammaBox
We now compute the LRP-attribution with the EpsilonGammaBox Composite.
[21]:
# use the VGG-specific canonizer (alias for SequentialMergeBatchNorm, only
# needed with batch-norm)
canonizer = VGGCanonizer()
# the EpsilonGammaBox composite needs the lowest and highest values, which are
# here for ImageNet 0. and 1. with a different normalization for each channel
low, high = transform_norm(torch.tensor([[[[[0.]]] * 3], [[[[1.]]] * 3]]))
# create a composite, specifying arguments and the canonizers
composite = EpsilonGammaBox(low=low, high=high, canonizers=[canonizer])
# choose a target class for the attribution (label 437 is lighthouse)
target = torch.eye(1000)[[437]]
# create the attributor, specifying model and composite
with Gradient(model=model, composite=composite) as attributor:
# compute the model output and attribution
output, attribution = attributor(data, target)
print(f'Prediction: {output.argmax(1)[0].item()}')
Prediction: 319
Visualize the attribution:
[22]:
# sum over the channels
relevance = attribution.sum(1)
# create an image of the visualize attribution
img = imgify(relevance, symmetric=True, cmap='coldnhot')
# show the image
display(img)

3.2 LRP with modified EpsilonGammaBox and ignored BatchNorm
We can modify the EpsilonGammaBox by changing the epsilon/ gamma, and supplying different layer mappings. Here, we explicitly ignore the BatchNorm layers, instead of merging them in the adjacent linear layer by not supplying the VGGCanonizer:
[23]:
# the EpsilonGammaBox composite needs the lowest and highest values, which are
# here for ImageNet 0. and 1. with a different normalization for each channel
low, high = transform_norm(torch.tensor([[[[[0.]]] * 3], [[[[1.]]] * 3]]))
# create a composite, specifying arguments and canonizers
composite = EpsilonGammaBox(
low=low,
high=high,
canonizers=[],
gamma=0.5, # change the gamma for all layers
epsilon=0.1, # change the epsilon for all layers
layer_map=[
(BatchNorm, Pass()), # explicitly ignore BatchNorm
]
)
# choose a target class for the attribution (label 437 is lighthouse)
target = torch.eye(1000)[[437]]
# create the attributor, specifying model and composite
with Gradient(model=model, composite=composite) as attributor:
# compute the model output and attribution
output, attribution = attributor(data, target)
print(f'Prediction: {output.argmax(1)[0].item()}')
Prediction: 319
Visualize the attribution:
[24]:
# sum over the channels
relevance = attribution.sum(1)
# create an image of the visualize attribution
img = imgify(relevance, symmetric=True, cmap='coldnhot')
# show the image
display(img)

3.3 LRP with custom NameMapComposite
Here we demonstrate how rules can be assigned on a name-base using the abstract NameMapComposite. Note that this particular case will only work with VGG11-bn, so we redefine the model.
[25]:
# load the model and set it to evaluation mode
weights = VGG11_BN_Weights.DEFAULT if use_trained_weights else None
model = vgg11_bn(weights=weights).eval()
We can take a look at all leaf modules by doing the following:
[26]:
leaves = [
(name, module)
for name, module in model.named_modules()
if not [*islice(module.children(), 1)]
]
maxlen = max(len(name) for name, _ in leaves)
print('\n'.join(f'{name:{maxlen}s}: {module}' for name, module in leaves))
features.0 : Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
features.1 : BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
features.2 : ReLU(inplace=True)
features.3 : MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
features.4 : Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
features.5 : BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
features.6 : ReLU(inplace=True)
features.7 : MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
features.8 : Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
features.9 : BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
features.10 : ReLU(inplace=True)
features.11 : Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
features.12 : BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
features.13 : ReLU(inplace=True)
features.14 : MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
features.15 : Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
features.16 : BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
features.17 : ReLU(inplace=True)
features.18 : Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
features.19 : BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
features.20 : ReLU(inplace=True)
features.21 : MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
features.22 : Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
features.23 : BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
features.24 : ReLU(inplace=True)
features.25 : Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
features.26 : BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
features.27 : ReLU(inplace=True)
features.28 : MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
avgpool : AdaptiveAvgPool2d(output_size=(7, 7))
classifier.0: Linear(in_features=25088, out_features=4096, bias=True)
classifier.1: ReLU(inplace=True)
classifier.2: Dropout(p=0.5, inplace=False)
classifier.3: Linear(in_features=4096, out_features=4096, bias=True)
classifier.4: ReLU(inplace=True)
classifier.5: Dropout(p=0.5, inplace=False)
classifier.6: Linear(in_features=4096, out_features=1000, bias=True)
We can look at the architecture and then assign the rules directly to the names:
[27]:
name_map = [
(['features.0'], Flat()), # Conv2d
(['features.1'], Pass()), # BatchNorm2d
(['features.2'], Pass()), # ReLU
(['features.3'], Norm()), # MaxPool2d
(['features.4'], ZPlus()), # Conv2d
(['features.5'], Pass()), # BatchNorm2d
(['features.6'], Pass()), # ReLU
(['features.7'], Norm()), # MaxPool2d
(['features.8'], ZPlus()), # Conv2d
(['features.9'], Pass()), # BatchNorm2d
(['features.10'], Pass()), # ReLU
(['features.11'], ZPlus()), # Conv2d
(['features.12'], Pass()), # BatchNorm2d
(['features.13'], Pass()), # ReLU
(['features.14'], Norm()), # MaxPool2d
(['features.15'], ZPlus()), # Conv2d
(['features.16'], Pass()), # BatchNorm2d
(['features.17'], Pass()), # ReLU
(['features.18'], ZPlus()), # Conv2d
(['features.19'], Pass()), # BatchNorm2d
(['features.20'], Pass()), # ReLU
(['features.21'], Norm()), # MaxPool2d
(['features.22'], ZPlus()), # Conv2d
(['features.23'], Pass()), # BatchNorm2d
(['features.24'], Pass()), # ReLU
(['features.25'], ZPlus()), # Conv2d
(['features.26'], Pass()), # BatchNorm2d
(['features.27'], Pass()), # ReLU
(['features.28'], Norm()), # MaxPool2d
(['avgpool'], Norm()), # AdaptiveAvgPool2d
(['classifier.0'], Epsilon()), # Linear
(['classifier.1'], Pass()), # ReLU
(['classifier.2'], Pass()), # Dropout
(['classifier.3'], Epsilon()), # Linear
(['classifier.4'], Pass()), # ReLU
(['classifier.5'], Pass()), # Dropout
(['classifier.6'], Epsilon()), # Linear
]
Now we can use the name-map to create the composite:
[28]:
# use the VGG-specific canonizer (alias for SequentialMergeBatchNorm, only
# needed with batch-norm)
canonizer = VGGCanonizer()
# create a composite, specifying arguments and canonizers
composite = NameMapComposite(
name_map=name_map,
canonizers=[canonizer],
)
# choose a target class for the attribution (label 437 is lighthouse)
target = torch.eye(1000)[[437]]
# create the attributor, specifying model and composite
with Gradient(model=model, composite=composite) as attributor:
# compute the model output and attribution
output, attribution = attributor(data, target)
print(f'Prediction: {output.argmax(1)[0].item()}')
Prediction: 31
Visualize the attribution:
[29]:
# sum over the channels
relevance = attribution.sum(1)
# create an image of the visualize attribution
img = imgify(relevance, symmetric=True, cmap='coldnhot')
# show the image
display(img)
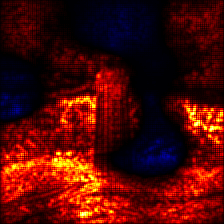
4. ResNet18
We initialize the ResNet18 model and optionally load the hyperparameters.
[30]:
# load the model and set it to evaluation mode
weights = ResNet18_Weights.DEFAULT if use_trained_weights else None
model = resnet18(weights=weights).eval()
4.1 LRP with EpsilonPlusFlat
Compute the LRP-attribution using the EpsilonPlusFlat Composite:
[31]:
# use the ResNet-specific canonizer
canonizer = ResNetCanonizer()
# create a composite, specifying the canonizers
composite = EpsilonPlusFlat(canonizers=[canonizer])
# choose a target class for the attribution (label 437 is lighthouse)
target = torch.eye(1000)[[437]]
# create the attributor, specifying model and composite
with Gradient(model=model, composite=composite) as attributor:
# compute the model output and attribution
output, attribution = attributor(data, target)
print(f'Prediction: {output.argmax(1)[0].item()}')
Prediction: 931
Visualize the attribution:
[32]:
# sum over the channels
relevance = attribution.sum(1)
# create an image of the visualize attribution
img = imgify(relevance, symmetric=True, cmap='coldnhot')
# show the image
display(img)

4.2 LRP with EpsilonGammaBox
Compute the LRP-attribution using the EpsilonGammaBox Composite:
[33]:
# use the ResNet-specific canonizer
canonizer = ResNetCanonizer()
# the ZBox rule needs the lowest and highest values, which are here for
# ImageNet 0. and 1. with a different normalization for each channel
low, high = transform_norm(torch.tensor([[[[[0.]]] * 3], [[[[1.]]] * 3]]))
# create a composite, specifying the canonizers, if any
composite = EpsilonGammaBox(low=low, high=high, canonizers=[canonizer])
# choose a target class for the attribution (label 437 is lighthouse)
target = torch.eye(1000)[[437]]
# create the attributor, specifying model and composite
with Gradient(model=model, composite=composite) as attributor:
# compute the model output and attribution
output, attribution = attributor(data, target)
print(f'Prediction: {output.argmax(1)[0].item()}')
Prediction: 931
Visualize the attribution:
[34]:
# sum over the channels
relevance = attribution.sum(1)
# create an image of the visualize attribution
img = imgify(relevance, symmetric=True, cmap='coldnhot')
# show the image
display(img)
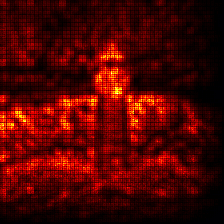
4.3 LRP with custom LayerMapComposite
In this demonstration, we want to ignore the BatchNorm layers and attribute the residual connections not by contribution but equally. This setup requires no Canonizer, but a special Composite which ignores the BatchNorm modules for LRP by assigning them the Pass rule.
[35]:
# the ZBox rule needs the lowest and highest values, which are here for
# ImageNet 0. and 1. with a different normalization for each channel
low, high = transform_norm(torch.tensor([[[[[0.]]] * 3], [[[[1.]]] * 3]]))
# create a composite, specifying the canonizers, if any
composite = SpecialFirstLayerMapComposite(
# the layer map is a list of tuples, where the first element is the target
# layer type, and the second is the rule template
layer_map=[
(Activation, Pass()), # ignore activations
(AvgPool, Norm()), # normalize relevance for any AvgPool
(Convolution, ZPlus()), # any convolutional layer
(Linear, Epsilon(epsilon=1e-6)), # this is the dense Linear, not any
(BatchNorm, Pass()), # ignore BatchNorm
],
# the first map is only used once, to the first module which applies to the
# map, i.e. here the first layer of type AnyLinear
first_map = [
(AnyLinear, ZBox(low, high))
]
)
# choose a target class for the attribution (label 437 is lighthouse)
target = torch.eye(1000)[[437]]
# create the attributor, specifying model and composite
with Gradient(model=model, composite=composite) as attributor:
# compute the model output and attribution
output, attribution = attributor(data, target)
print(f'Prediction: {output.argmax(1)[0].item()}')
Prediction: 931
Visualize the attribution:
[36]:
# sum over the channels
relevance = attribution.sum(1)
# create an image of the visualize attribution
img = imgify(relevance, symmetric=True, cmap='coldnhot')
# show the image
display(img)
